Archive
Slowing source audio for interpreting classes in the digital audio lab
- To judge from listening to Simult. Lesson 1, text 2 on Acebo Interpreter’s Edge (ISBN 1880594323), I am wondering whether some of our students (= personalization) would need this audio to be simplified, to gain the benefit of a well-adjusted i+1? I can pre-process the audio :
- Where the flatlines = natural pauses are in above graph, insert a audio signal as where students can press voice insert recording, Example:

- We can also insert a pause and a cue at the beginning and end to set students a limit how long they can interpret, but if students operate the player manually, there is no teacher control and no exam condition, and the students having to manage the technology tends to distract from the language practice.
- Slow down the audio without changing the pitch (just have to make sure not to overdo it, else will sound like drunken speech – my time stretching software would be able to avoid “drunken speech” syndrome, but I have not been able to work on it since briefly for IALLT in Summer 2011 for 3 years now…)
- We can use this adjusted with the Sanako grouping feature to personalize instruction (find the right i+1 for each of your student, useful if there are considerable variations in their proficiency): How to group students into sessions (in 3 different ways) goo.gl/JgXUP/.
- Where the flatlines = natural pauses are in above graph, insert a audio signal as where students can press voice insert recording, Example:



Protected: Elti0162 Syllabus with learning materials for listening and speaking
Quizlet.com for Vocabulary learning practice
Neallt 2014 is featuring a presentation on “Using Quizlet.com to generate and share vocabulary activities” (William Price, University of Pittsburgh). I cannot attend, but the program inspired me to hold my own sneak preview:
Quizlet.com is yet another site that provides a variety of flashcard and quiz activities for a given wordlist. A nice example is the “Speller”activity – which proves a text-to-speech generated aural cue for dictation (not included in this video):
Or step-by-step:
 Unfortunately, the AI seems limited to only 1-1 L1-L2 relationships (which precludes how vocabulary seems to be learnt best: in phrasal contexts):
Unfortunately, the AI seems limited to only 1-1 L1-L2 relationships (which precludes how vocabulary seems to be learnt best: in phrasal contexts):

Feedback on “wrong” user input is color red, aural and visual presentation of the correct form: 
Then the application re-prompts for user input and allows user correction:

This is a “Test activity. Foreign language character input seems easy (but does beg the question since the inputs appear only when they are needed…)


Mix-and-match is called Scatter:

Here is the activity overview: ![]()
Wait, there is more: 
Quizlet supports many dozen languages, including non-western, including ancient, not differentiating between modern and ancient Greek, but the browsing capabilities – admittedly a hard task – are somewhat flat (search and language)):

And boasts 20 million sets (as of today – many consisting of 2 terms or few more). As so often, usefulness for class instruction hinges on the availability of textbook-aligned vocabulary lists. However, if you have them with your textbooks, Quizlet makes it automatic to generate uploaded materials into exercises.
However, as said, you may not like how much you have to dumb it down.
How students need to work around Sanako startup issues at start of 2014
UPDATE: Step 1 is not necessary anymore, Step2 (Microphone click) still is.
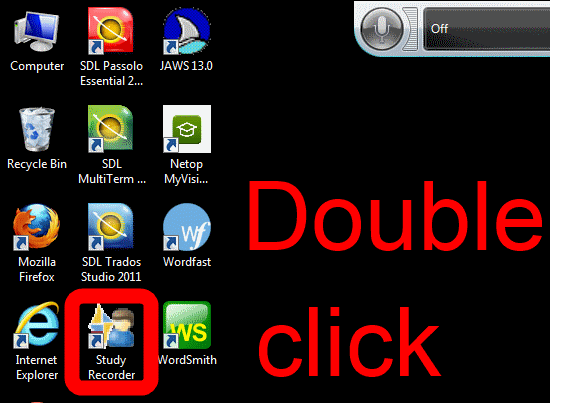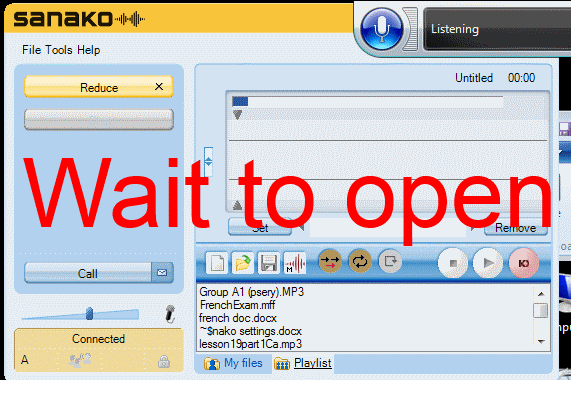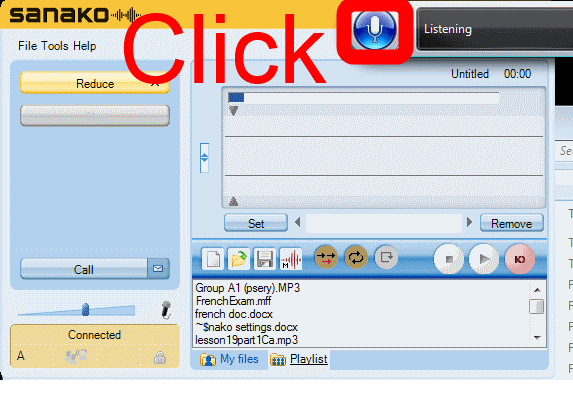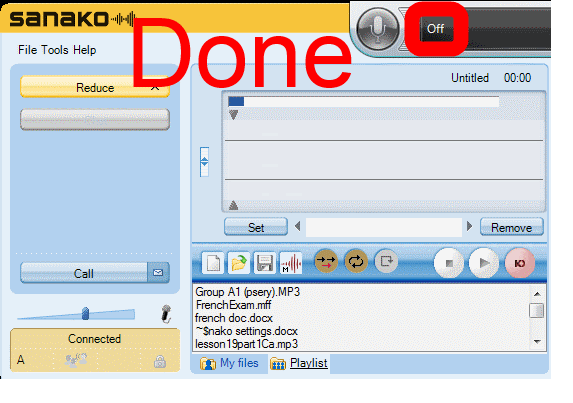
How to get started with the new text-to-speech support in Sanako 7
- With the new text-to-speech feature, students can generate their own pronunciation help:


- Using the button:Advanced settings, you can even
- vary the speed of,
- insert bookmarks to use with Sanako player
- or insert thinking pauses for the learner into the audio – excellent ideas, I find
 !
!
- Unfortunately, the LRC currently has voices only for English and Mandarin. Extra voices cost extra
 .
. - Then there is Google translate text-to-speech, but that cannot be saved to file.


Proposing for a free Moodle audio recorder: Technical options and faculty needs survey results
- Current popular options for a free Moodle audio recorder:
- Nanogong is a popular, feature-rich and simple recorder that go entangled in the recent java politics and security scares. Since the company has a non-free offering, chances are higher it will get updated to address these security warnings. It seems the long-term outlook for java in the enterprise is excellent, but i cannot judge the long term outlook for java as a client/in-browse solution.
- Poodle which played the 2nd fiddle to Nanogong for most of the time, seems to have caught up to Nanogong based on the above. that it is "server based" – but on theirs, not ours – Poodle has a freemium business model (could be an issue). Does this include the audio compression load? Does this have FERPA implications (and can they be resolved like with Kaltura)?
- Paul Nicholls has a number of flash-based popular audio recorder plugins , where record assignment submission seems to have superseded record assignment type for newer versions of Moodle, and assignment type offers student recording, while Record Audio repository complements this with teacher recording (and the same interface; i am not sure i understand which end user setup is required for repository).
- In the results of faculty survey on learning needs (sum of 0-centered Likert-scale), I find notable
- that teacher recording is considered almost as vital as student recording, and
- that most faculty even would be willing to deal with some complexity for the additional learning features that some of these recorders offer (Nanogong especially).
|
Question_text |
Rank |
|
It is important that my students can record their speech in my Moodle course (without need for separate software and file upload). |
14 |
|
It is important that the setup work that the teacher has to do before being able to assign audio recorder is minimal. |
13 |
|
It is that the teacher can record her voice in Moodle (without need for separate software and file upload), providing oral instead of written cues or feedback. |
11 |
|
Simplicity is more important to me than feature richness (controlling volume, limiting the amount of time a student can record, maximum number of recordings, Recordings can be slowed down or sped up , Peer review of recordings). |
7 |
|
I expect my students to have a microphone connected to or built-in to their home computer. |
5 |
|
It is important that other media than audio can be "recorded" (video (outside of Kaltura), webcam snapshots, whiteboard drawings). |
5 |
How a teacher can use NanoGong’s plugin for the HTML editor to easily send their own audio to students
- The rich HTML editor recorder plug-in is supposed to make it easier for the teacher (than other recorders that require the teacher to save to file and upload the file to a Moodle activity). Here is how it can work:
- Add an activity which includes the rich HTML editor plugin, e.g. a page.
- Click on the loudspeaker icon denotes NanoGong among the editor tools.

- A window will open that includes the recorder JAVA applet (you may have to bypass Java warnings):

- Click the red record button and speak.
- When done, click insert.
- Result:

- Note, however, that so far I have run into issues actually displaying this teacher-added NanoGong recorder content.



Search Rhapsodie, a syntactic and prosodic Treebank of spoken French
- The Rhapsodie Treebank is made up of “57 short samples of spoken French (5 minutes long on average, amounting to 3 hours of speech and a 33 000 word corpus)” endowed with an orthographical phoneme-aligned transcription”.
- Rhapsodie can be searched at http://www.projet-rhapsodie.fr/queryql.html:

- View list, read (1) text or (2”phonetic transcription, click (3) and (4) to listen to found segment

- You can also search for text and download:

- The best is obviously the markup and query language – and hence has a learning curve.





Questions? Read the About. Or just ask me a quick Our Databases: Resources with calendars -- Language learning material Moodle Sites, multimedia files -- films


FAQs for LRC student staff or for students or for teachers. To search our FAQs, in the browser addressbar, add after "https://plagwitz.wordpress.com/feed/?tag=faqs+/" "+TAG1" (from tag cloud below) OR "https://plagwitz.wordpress.com/feed/tag=faqs
&category_name=" "CAT1" (from category hierarchy below). OR search both categories and tags, and multiple TAGs/CATs (connect with "," for OR-search, with "+" for AND-search), like so: https://plagwitz.wordpress.com/feed/?tag=TAG1+TAG2+...TAGn&category_name=CAT1
+CAT2+...CATn"
Other ways to find help
If you cannot find it here, look there: 5,500 Language-Learning Links and Programs for learning or teaching 150 languages
Shortcuts:Our Lists, Our Maps, LRC Staff Moodle Site,LRC Project Moodle Site, 49erexpress, UNCC Moodle, Student Recordings: s:claslcslrcsanakostudent
Learning usage samples: Sanako oral exam, Kaltura webcam presentation, Dictation with speech recognition, Sanako written exam, Chinese and Japanese interactive stroke-order practice
Test the Sanako Installer, Webbrowser Popup Konfigurator for XP, or Windows7, faster LRC TeacherPC Log-in Let MS facilitate diacritics writing by installing for you US-International keyboard layout
This is my personal blog (Google+). The views expressed on these pages are mine alone and not those of my employer. The information in this weblog is provided “AS IS” with no warranties, and confers no rights.
